In this first chapter we use R and nothing but R. Figure 1.1 shows the R GUI (graphical user interface) that you get to see when you open R. In this first chapter you only need to use this R Gui. In the next chapter we will switch to the RStudio IDE, but for now, let’s stick to the very basics.
Figure 1.1: The R GUI
1.1 R as a calculator
One of the simplest ways to use R is to perform some basic calculations. You just need to know some basic symbols, which are mostly self-evident.
4-1# addition
[1] 3
4/2# division
[1] 2
5^2# five to the power of two
[1] 25
sqrt(4) # sqrt = square root
[1] 2
(34-4)+(5+4) # use brackets
[1] 39
pi # 3.1415...
[1] 3.141593
log(x =25, base =5) # logarithm of 25 to the base 5
[1] 2
exp(x =2) # e^2 = 2.7182^2
[1] 7.389056
1.2 R functions
In R, we work with functions. A function has a name and arguments: Name(argument, argument, ...).
In very simple terms: a function “does something” with its arguments. There is at least one argument with necessary input (you need something to apply the function to). And there are often multiple extra arguments to tweak options regarding how the function is applied. For example, we wish to round the result of the quotient \(25/6\) (= 4.1666667) to two decimal places. For this we use the function round():
The first argument is the minimally required input, while the second is optional, that is to say that R has a default setting for the number of digits. Compare:
round(x =25/6)
[1] 4
Strictly speaking, we don’t need to write the names of the arguments (here: “x =” and “digits =”), but it makes the code more readable. It’s also my experience that not using the argument names is one reason why R-code can be quite opaque. Compare the code above with the one below.
round(25/6, 2)
[1] 4.17
You get the same result, but the former code with the argument names provides more information to the user; you need to remember what the second argument does. Moreover, documenting your code is always a good idea if you want to share your code in the spirit of Open Science.
Similarly:
ceiling(5.67)
[1] 6
floor(5.67)
[1] 5
1.3 Packages
When you open R, you automatically open a number of packages. Base-R is one such package.
Opening a package is like taking a book from a library with functions and data that allows you to work in R.
Besides base-R, there are many other packages written by R users that contain a specific sets of functions and datasets. You can look at these packages as specialised toolboxes.
To use those other packages, you must first install these via install.packages() and then open them using library().
install.packages("bayesplot")library("bayesplot")
When you use a particular package in your research, make sure to cite the package in your final output (article, report, book, thesis, etc.). That way you give proper credit to the package author(s). Use the function citation("package") to get the reference(s):
citation("bayesplot")
To cite the bayesplot R package:
Gabry J, Mahr T (2025). "bayesplot: Plotting for Bayesian Models." R
package version 1.15.0, <https://mc-stan.org/bayesplot/>.
To cite the bayesplot paper 'Visualization in Bayesian workflow':
Gabry J, Simpson D, Vehtari A, Betancourt M, Gelman A (2019).
"Visualization in Bayesian workflow." _J. R. Stat. Soc. A_, *182*,
389-402. doi:10.1111/rssa.12378 <https://doi.org/10.1111/rssa.12378>.
To see these entries in BibTeX format, use 'print(<citation>,
bibtex=TRUE)', 'toBibtex(.)', or set
'options(citation.bibtex.max=999)'.
And always cite R and give credit to the R Core Team:
citation()
To cite R in publications use:
R Core Team (2025). _R: A Language and Environment for Statistical
Computing_. R Foundation for Statistical Computing, Vienna, Austria.
<https://www.R-project.org/>.
A BibTeX entry for LaTeX users is
@Manual{,
title = {R: A Language and Environment for Statistical Computing},
author = {{R Core Team}},
organization = {R Foundation for Statistical Computing},
address = {Vienna, Austria},
year = {2025},
url = {https://www.R-project.org/},
}
We have invested a lot of time and effort in creating R, please cite it
when using it for data analysis. See also 'citation("pkgname")' for
citing R packages.
R now knows that x is the “name” for the value of \(10\). Let’s evaluate x:
x
[1] 10
Actually, we have used the function print() here, without spelling it out explicitly:
print(x)
[1] 10
Note that the assignment operator (‘<-’) consists of the two characters ‘<’ (“less than”) and ‘-’ (“minus”). Some textbooks use “=” as an alternative. It is also possible (but never done) to use the assign() function:
As a beginner, there are more than enough functions in base-R and the existing packages. So in this course we will not create our own functions.
1.5 Vectors
One of the most important data structures in R is the vector, which is basically a row of similar data (e.g. all numeric objects, all integers, all characters). We create a vector of 5 numbers and give it the name mydata:
mydata <-c(4,6,8,2,7)mydata
[1] 4 6 8 2 7
To create a vector, we use the function c(), which stands for “concatenate” or “combine”. Then we apply a function to the vector. For instance, how many elements does mydata include? (Or, how long is the vector?):
length(mydata)
[1] 5
Most functions in R are “vectorized”, which means that the function operates on all elements of the vector.
There’s no need in R to write a “loop” to act on every element (this is getting a bit technical, but this is a an important difference between R and other programming languages).
For instance, we wish to add \(3\) to every element of mydata:
mydata+3
[1] 7 9 11 5 10
It’s also possible to create a vector of “words” (or better still of “characters”, sometimes refered to as “strings”)
Min. 1st Qu. Median Mean 3rd Qu. Max.
3.00 14.75 23.00 22.28 26.75 34.00
At this stage, it might be worthwhile to have a look at the “objects” that we have created:
ls()
[1] "mydata" "myfriends" "sortedorder" "square"
[5] "WordsPerSentence" "x" "y"
You can remove objects with rm():
rm("y") # to remove y, an object that we created earlier
To remove all objects:
rm(list=ls())
1.7 Categorical data
In statistics, we distinguish between two kinds of variables:
continuous variable (also called “quantitative”)
categorical variable (also called “qualitative”)
Continuous variables are based on measurements (e.g., length, number of words, height, etc.) Categorical variables have a limited number of categories as their values (e.g., Correctness with “correct” vs. “incorrect”, Animacy with “animate” vs. “inanimate”)
For example, let’s say we asked 10 participants about their educational level, operationalized as a three level categorical variable:
We transform the character variable to a factor, which is more convenient (and required) for a statistical analysis. A factor variable includes different levels.
EduLevel is now a factor variable with three categories or levels. R assigns a number to every category.
Levels are assigned alphabetically. This can be overruled and the levels can be binned (something that we will do later in this course).
We summarize the factor variable by means of the table() function.
table(EduLevel)
EduLevel
ba high ma
2 4 4
Proportions or fractions are calculated with prop.table().
prop.table(table(EduLevel))
EduLevel
ba high ma
0.2 0.4 0.4
Notice that we have created a so-called “nested” function. This can be avoided by using a so-called pipe function (“|>” or “%>%”):
table(EduLevel) |>prop.table()
EduLevel
ba high ma
0.2 0.4 0.4
1.8 Missing values
Missing values are indicated by “NA”.
Here we create a vector RT (Reaction time), with one missing variable:
RT <-c(345, 367, 440, 438, NA, 500, 270)is.na(RT)
[1] FALSE FALSE FALSE FALSE TRUE FALSE FALSE
is.na() is a logical function. The output of the function is another vector with TRUE or FALSE. So 345 is not a missing value, so this gets the value “FALSE”, 367 is not a missing value, so this gets the value “FALSE”, etc.
We can extract which observation is a missing value by means of which():
which(is.na(RT)) # again a nested function
[1] 5
So the fifth value of the vector RT is a missing value.
But how many missing values are there?
length(which(is.na(RT)))
[1] 1
1.9 Logical operators
Is \(5\) larger than \(3\)?
5>3
[1] TRUE
Is \(x\) smaller \(y\)?
x <-5# create an object x and assign this x the number five y <-16# create an object y and assign this y the number sixteen x < y # is x smaller than x?
[1] TRUE
Other useful logical operators:
x <=5# smaller than or equal to
[1] TRUE
y >=20# larger than or equal to
[1] FALSE
y ==16# equal to
[1] TRUE
x !=5# different from
[1] FALSE
1.10 Index function
Square brackets are important symbols in R. It allows you to extract elements from an object. We call this an index function.
For instance, here we extract the third element of the vector score.
score <-c(18, 12, 17)score[3]
[1] 17
letters is an existing object in base-R and consists of the letters (in lower case) of the alphabet.
alfabet <- lettersalfabet
[1] "a" "b" "c" "d" "e" "f" "g" "h" "i" "j" "k" "l" "m" "n" "o" "p" "q" "r" "s"
[20] "t" "u" "v" "w" "x" "y" "z"
We use the index function, i.e., the square brackets, to extract different elements:
One of the major advantages of R is its capability to perform simulations. This allows one to bypass the need for actual experiments and instead conduct virtual experiments. In contemporary empirical research, this approach is crucial as it enables the evaluation of hypotheses and the assessment of their plausibility. A fundamental step in this process is the creation or selection of a sample. In this context, we will generate a dataset consisting of \(N = 10\) elements and subsequently draw a random sample of 5 elements from it.
Here we simulate tossing a coin twenty times. There are two possible events: head or tail. Both have an equal probability (\(50\%\)). Suppose that we have a binary outcome variable or the outcome of an process that generates two possible events of which one event is taken to occur with a \(70\%\) probability. We can simulate this by adapting the argument prob:
With rnorm() we can draw a random sample from a normal distribution. We draw a random sample of \(N=200\) observations from a normal distribution with mean \(\mu=4.5\) and standard deviation \(\sigma=2\).
Some basic visualisations of continuous and categorical variables. No shining bells or whistles here, just the very basics.
1.12.1 Histogram
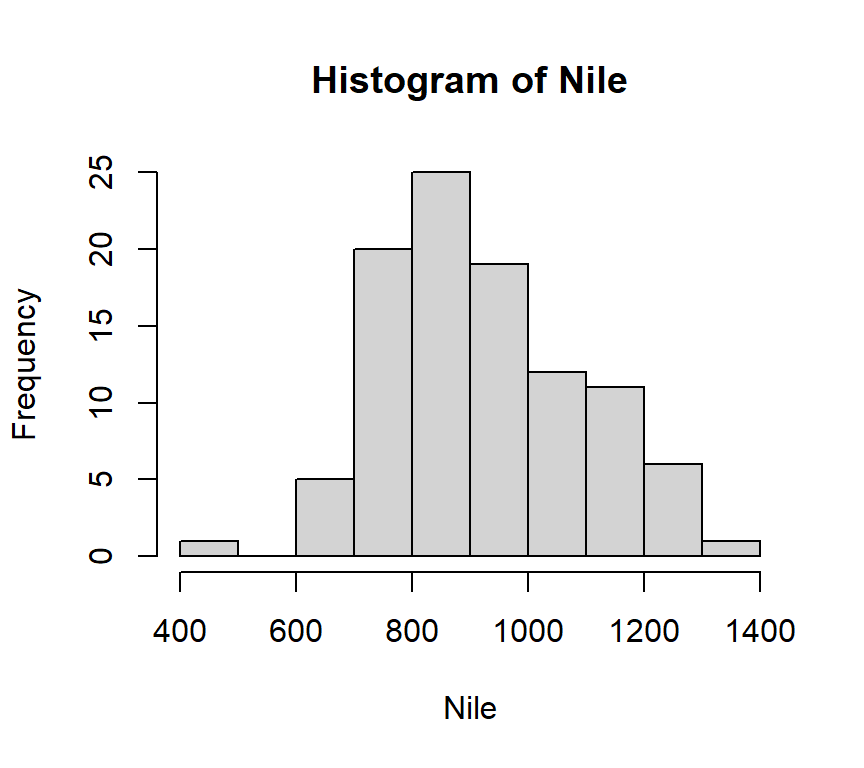
Figure 1.2 is based on what is arguably the simplest code ever^[ thank you, Norman Matloff, for the inspiration. I invite every reader of this course book to take Matloff’s online course https://github.com/matloff/fasteR)]:
hist(Nile)
Figure 1.2: A histogram of the Nile dataset.
Nile is a dataset from the base-R package. The simplicity of the code illustrates how R (and its predecessor S) was developed as a quintessential statistical programming language.
We will now create a histogram based on a dataset that we generate ourselves.
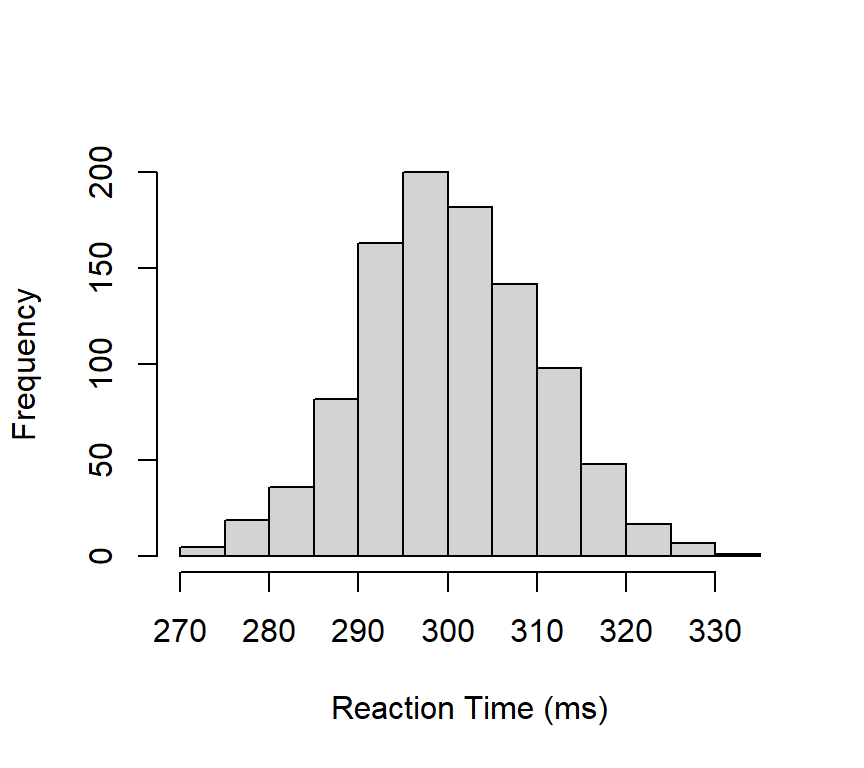
Let’s create a continuous variable ReactionTime with \(N=1000\) observations sampled from a normal distribution.
We can assume a mean reaction time of \(300\,ms\) and a standard deviation of \(10\,ms\). ^[This is an incorrect assumption. Reaction times are highly skewed and lognormally distributed at best. But his will do for now].
Next, we apply the hist() function to our ReactionTime object, as shown in Figure Figure 1.3.”
1ReactionTime <-rnorm(n =1000, mean =300, sd =10)2hist(ReactionTime,3main ="",4ylab ="Frequency",xlab ="Reaction Time (ms)")
1
We create the variable ReactionTime
2
we apply hist(); the first argument is the data that we wish to visualise
3
main = “” creates a title on top of the figure, but here we keep this empty
4
we add a label to both axes.
Figure 1.3: A histogram of Reaction Time
1.12.2 Density curve
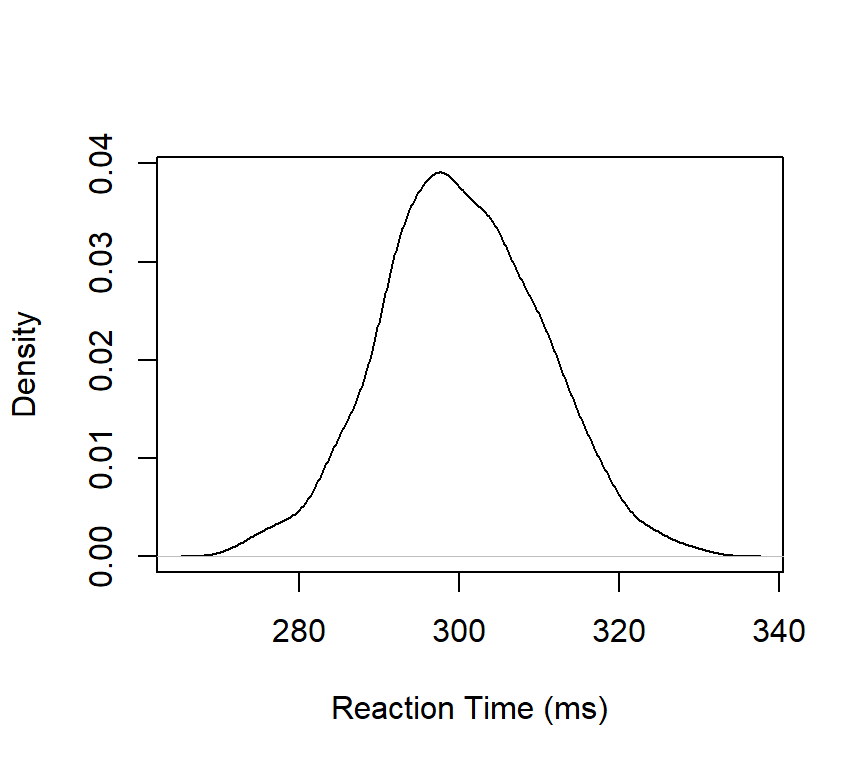
Figure 1.4 visualizes the same dataset or vector ReactionTime by means of a density curve.
1densRT <-density(ReactionTime)2plot(densRT,main ="", ylab ="Density", xlab ="Reaction Time (ms)")
1
First, a density object is created
2
plot() visualises the density object (R “knows” that a density curve should be plotted), and tweak some aesthetics
Figure 1.4: A density curve for Reaction Time.
1.12.3 Boxplot
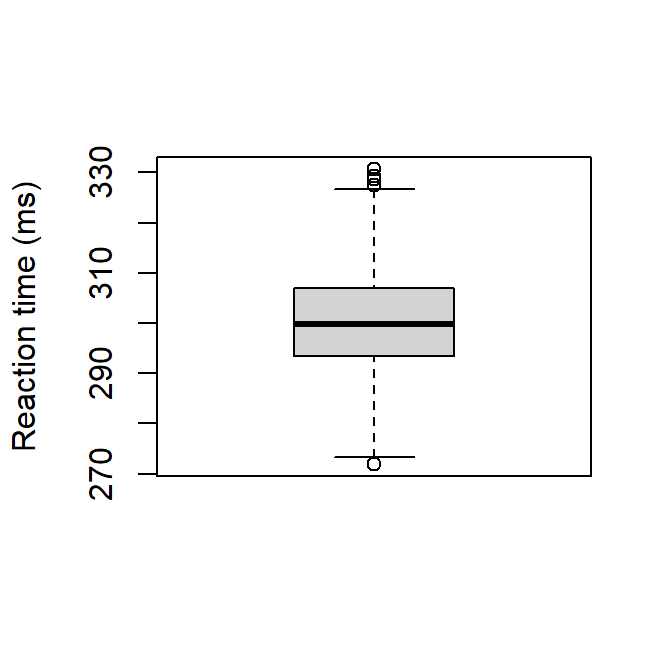
Figure 1.5 visualizes Reactiontime by means of a boxplot. A boxplot visualizes location values minimum, first quartile, median, third quartile, and maximum. Outliers are indicated as “o”. An outlier is defined as any observation that is more than 1.5 times the interquartile range removed from the nearest quartile. The IQR is the range between Q1 and Q3, i.e., the length of the box.
boxplot(ReactionTime, ylab ="Reaction time (ms)")
Figure 1.5: A boxplot of Reaction Time.
1.12.4 Stripchart
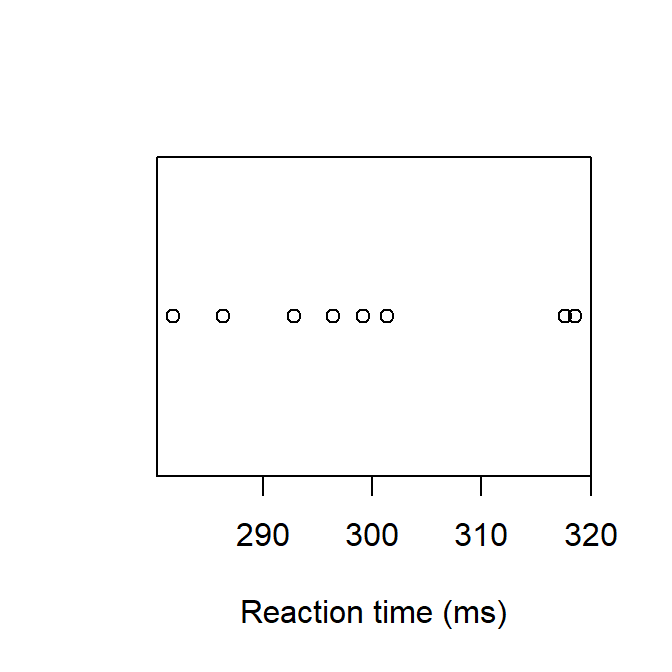
If there are only a few observations, a simple stripchart as in Figure 1.6 might suffice:
1sampleRT <-sample(x = ReactionTime, size =8)2stripchart(sampleRT,3xlab ="Reaction time (ms)",4pch =1)
1
Take a random sample from ReactionTime
2
apply strichart to the newly created sample
3
add a label to the horizontal axis
4
uses round points rather than the default square ones
Figure 1.6: A dot plot of Reacton Time.
1.12.5 Barplot
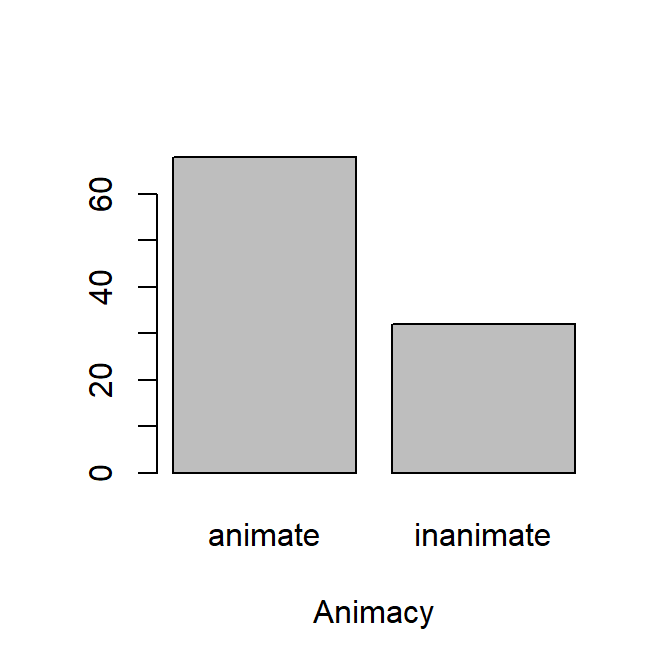
We create a factor vector “Animacy” with two values “animate” vs< “inanimate” with rep().
Before we can visualise the vector by means of a barplot, we first need to count the number of observations for each level of the variable.
tt <-table(Animacy)
Then we can apply barplot() to th etable object, which gives Figure 1.7.
barplot(tt,xlab ="Animacy")
Figure 1.7: A barplot of the variable Animacy.
1.tt is the object that was created with table()
2. xlab adds a label to the horizontal axis.
1.12.6 Scatterplot
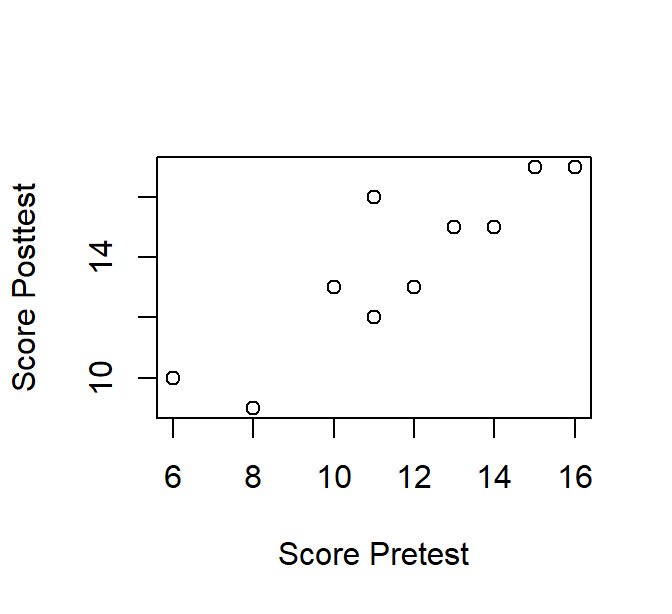
Table 1.1 presents a mock dataset for ten participants who performed a pre- and posttest.
Table 1.1: Pre- en Posttestscores
ID
Pretest
Posttest
1
13
15
2
8
9
3
11
16
4
12
13
5
16
17
6
15
17
7
11
12
8
6
10
9
10
13
10
14
15
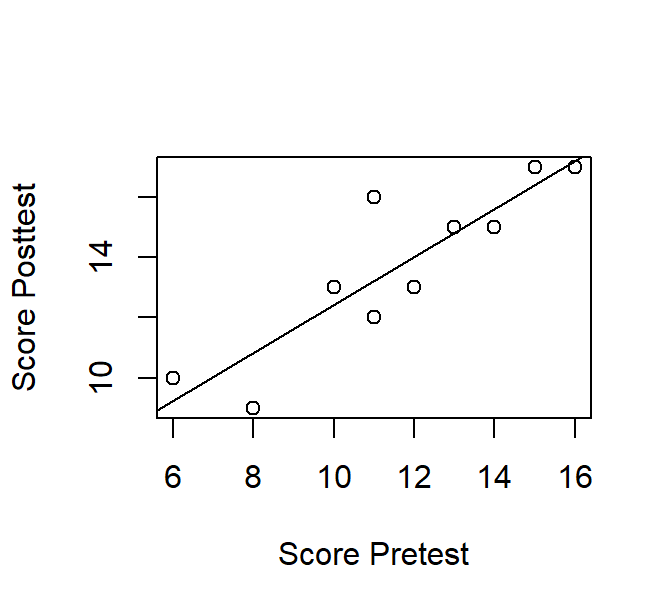
We wish to visualize the relationship between both scores by means of a scatterplot. We create two vectors, one for each test and apply the plot() function. Figure 1.8 shows the result.
Figure 1.8: A scatterplot of Pre- and Posttest scores.
To visualize a possible linear relationship, we can add a linear regression line with abline().
The coefficients of the line are extracted by means of the lm()function. Note that once again R knows what kind of “plot” to draw to create the scatterplot in Figure 1.9.
Figure 1.9: A scatterplot of Pre- and Posttest scores with a regression line.
1.13 Exercises
Exercise 1.1
Calculate the following.
7+8
15-8
the product of 23 and 34
2 raised to the power of 3
the square root of 25
sine of π/4
the expression \(\frac{(3 + 5) \times (2^3)}{\sqrt{16}}\)
Exercise 1.2
We measured the height of basketball players (in cm): 189, 190, 198, 210, 213, 234, 205, 207, 198, 199, 189, 203, 204, 207, 188, 187, 179, 209, 205, 204, 206, 200, 199, 198, 198, 206, 204, 175, 201.
Create a vector in R called “height” and assign the measurements to this object
How many observations are there?
What is the average height of the players?
Use R to calculate:
maximum
minimum
median
standard deviation
variance
Use a function to find help on the mean() function
R contains several datasets which are loaded automatically.
Open the dataset ToothGrowth.
Assign the name tg to the dataset ToothGrowth.
How many variables does tg have? (tip: use str())
Exercise 1.3
Create a vector “numbers” with all numbers from 1 to 20
Replace the third element with “NA”
What is the average of the vector numbers?
What is the sum of all numbers larger than \(10\)?
How many numbers are larger than \(15\)?
Extract the fourth element.
A lexical decision task returned the following results: {word, non-word, non-word, non-word, non-word, word, word, word, word}. Use R to calculate the proportion of words.
Exercise 1.4
Reconsider the height dataset that you created in Exercise 1.2.
Visualize the data by means of a yellow histogram.
Visualize the data by means of a blue horizontal boxplot and label the horizontal axis.
Take a random sample of 5 players and visualize the sample with a vertical stripchart.